0. TL;DR(摘要)
LXDAO S9 赛季的“良心杀”是一场围绕公共物品资金分配的治理模拟实验。6 个小组在不同主题下,对 5 个候选项目进行资金分配讨论与投票。实验呈现出 DAO 治理中典型的现实问题:公共物品定义不统一、评估框架缺失、信息不对称、参与度不足与缺少事后验证闭环。同时,游戏机制中的“好人/坏人”设定显著增强了博弈性,也放大了策略表达与集体偏见风险。
本报告在总结各组分配结果的基础上,进一步抽象出 5 个关键治理问题,并提出可落地的改进方向,最后给出一套“良心杀”机制优化建议(包含隐私与反博弈设计)。
1. 游戏机制简介:公共物品资金分配的治理模拟
本次 LXDAO S9 赛季的“良心杀”(Public Goods Funding)是一场面向社区成员的公共物品资金分配博弈实验。
核心规则
-
每个小组面对 5 个候选项目
-
共同分配一笔固定资金(如 100,000 USD)
-
目标是最大化公共物品价值,同时在讨论中处理策略与不确定性
讨论中出现的通用评估维度
-
项目价值:质量、覆盖范围、可及性、长期影响
-
分配策略:集中 vs 分散
-
治理意义:生态推动、协作效率、公平性
这一机制的价值在于:它不仅让参与者讨论“分配结果”,更让大家体验到真实 DAO 治理的核心难题——共识形成过程本身。
2. 各小组提案类型与分配结果概览
本次共 6 个小组参与:
-
4 组选择 Web3 教育专项
-
1 组选择 DAO 治理工具专项
-
1 组选择社区活动(Devcon/活动闭环)专项
这一分布本身反映了社区成员对“公共物品”的主流理解:教育与人才增长仍然是最容易形成共识的公共物品类型,而治理工具与活动型公共物品更偏向机制与体验层面的公共价值。
2.1 Hickerzed 小组 — Web3 教育专项(教育类公共物品)
项目主题:Web3 教育专项,资金池 100,000 USD。
该组聚焦 Web3 教育项目,候选项目包括 ETHBaga、Web3 DAO、Movement、WTF Academy、Openbuild 等。多数成员在讨论中强调:
-
教学质量与可及性 是核心评估尺度;
-
强调避免“平均主义”与“过度集中”,主张权重分配应兼顾长期价值和普惠性;
-
对 WTF Academy、ETHBaga 等具有普惠性和生态连接价值的项目给予更高倾斜;
-
对 Movement 这类区域性线下项目持相对谨慎态度,并认为其对全球性资金分配价值有限。
Hickerzed 小组分配结果
| 项目名称 | 最终获批资金 (USD) | 分配比例 |
|---|---|---|
| WTF Academy | 29,780.10 | 29.9% |
| ETHBaga | 25,956.70 | 26.1% |
| Openbuild | 25,699.44 | 25.8% |
| Web3 DAO | 15,113.48 | 15.2% |
| Movement | 3,029.24 | 3.0% |
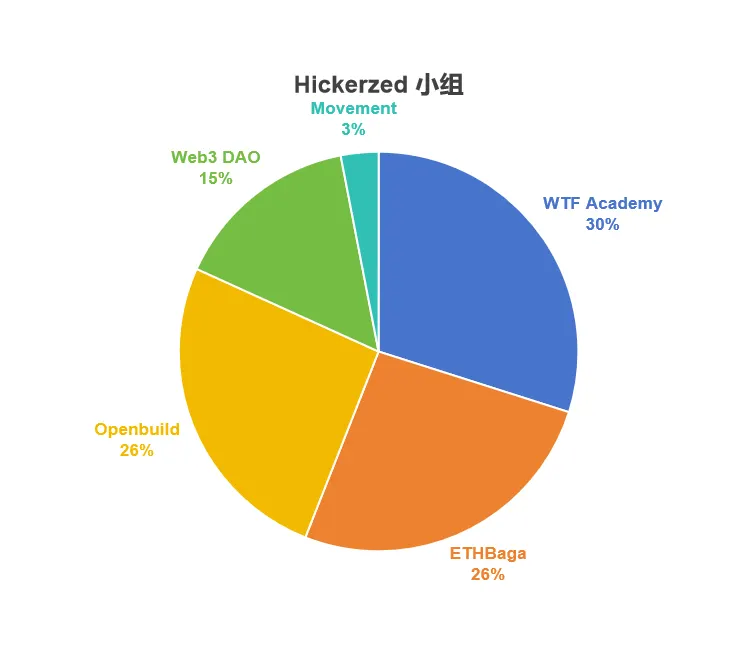
总结来看,该组形成的较广泛共识是:
![]() 教育类公共物品首要要解决“长期价值”和“覆盖面广”问题,同时避免项目因地域性/形式局限而导致资源浪费。
教育类公共物品首要要解决“长期价值”和“覆盖面广”问题,同时避免项目因地域性/形式局限而导致资源浪费。
2.2 LUWANA 小组 — Web3 教育专项(Resolved)
项目主题:Web3 教育专项,项目包括 ETHPanda、Web3 University、ETH Singapore、Bankless Academy、ShanHaiWoo。
该小组采用了 群众投票 + 小程序投票 的方式最终决定资金分配方向。讨论内容中出现了两类典型策略:
-
集中策略
认为资金应重点投入已经形成教育与社区结合闭环的项目,如 ETHPanda,避免资源被分散而削弱长期影响。
-
分散 + 观察策略
主张把资金一部分分配给稳定运营、覆盖面广的教育平台(如 Web3 University、Bankless Academy),一部分用于探索性项目(如 ShanHaiWoo)。
讨论中,成员们强调了:
-
结合 DAO 自身的 runway 和当前生态需要考虑资金分配策略,
-
不同项目的组织形式与当前阶段不同,资金分配中应体现多样性与稳健性。
LUWANA 小组分配结果
| 项目名称 | 应分配资金 (USD) | 分配比例 |
|---|---|---|
| ETHPanda | 57,000 | 57% |
| Bankless Academy | 15,000 | 15% |
| Web3University | 13,000 | 13% |
| ETH Singapore | 9,000 | 9% |
| ShanHaiWoo | 6,000 | 6% |
| 总计 | 100,000 | 100% |

2.3 Jintol 小组 — DAO 治理工具基金
项目主题:DAO 治理工具资金分配,候选项目包括 Snapshot、Tally、Agora、FairSharing、Coordinape。
该小组聚焦治理工具自身的生态价值与成熟度,主要策略包括:
-
核心聚焦 + 小额分散:优先支持被大范围使用或具有明显生态价值的治理基础设施,比如 Snapshot 和 Tally;在此基础上为创新性工具保留小额资金。
-
鼓励创新探索,如将资金留给 FairSharing 或 Coordinape 来试验贡献分配与社会激励机制。
他们的讨论体现了一个更系统性的思路——不只看一个项目的“普惠性”,还要看治理基础和生态稳定性:
一笔资金不应该全部押注单一项目,而是通过组合形成治理基础设施 + 创新实验的生态层次。
Jintol 小组分配结果
| 项目名称 | 应分配资金 (USD) | 分配比例 |
|---|---|---|
| Coordinape | 22,500 | 22.5% |
| FairSharing | 21,500 | 21.5% |
| Tally | 20,000 | 20.0% |
| Agora | 19,000 | 19.0% |
| Snapshot | 16,000 | 16.0% |
| 总计 | 100,000 | 100% |

2.4 Xiaohai x Draken 小组 — 教育生态 & 实践
该组的讨论核心同样围绕 Web3 教育类项目,但更着眼于组合策略:
-
倾向平衡集中与多元;
-
从“功能闭环视角”审视候选项目;
-
建议优先支持那些能兼顾教学与实践、覆盖多样受众的项目,如 Bankless Academy、Web3 University 等。
他们强调了资金配置不仅要覆盖高质量教育内容,也要兼顾社区实践与跨组织开放协作。
Xiaohai&Darken 小组分配结果
| 项目名称 | 应分配资金 (USD) | 分配比例 |
|---|---|---|
| ETHPanda | 34,040 | 34.04% |
| Web3 University | 19,770 | 19.77% |
| Bankless Academy | 17,370 | 17.37% |
| ShanHaiWoo (山海坞) | 16,950 | 16.95% |
| ETH Singapore | 11,860 | 11.86% |
| 总计 | 100,000 | 100.00% |

2.5 Echo 小组 — 教育资源 + 可持续性
Echo 小组围绕 Web3 教育资产展开,核心关注点是:
-
教育资源的持续可持续性;
-
教育类项目在 DAO 融资公信力上的体现(因为其 runway 短、未来面临融资挑战)。
虽然他们的完整讨论细节在摘要中不可见,但明确的是他们在强调:
-
长期价值大于短期项目热闹;
-
教育资源的覆盖面和可持续发展更适合作为公共物品支持重点。
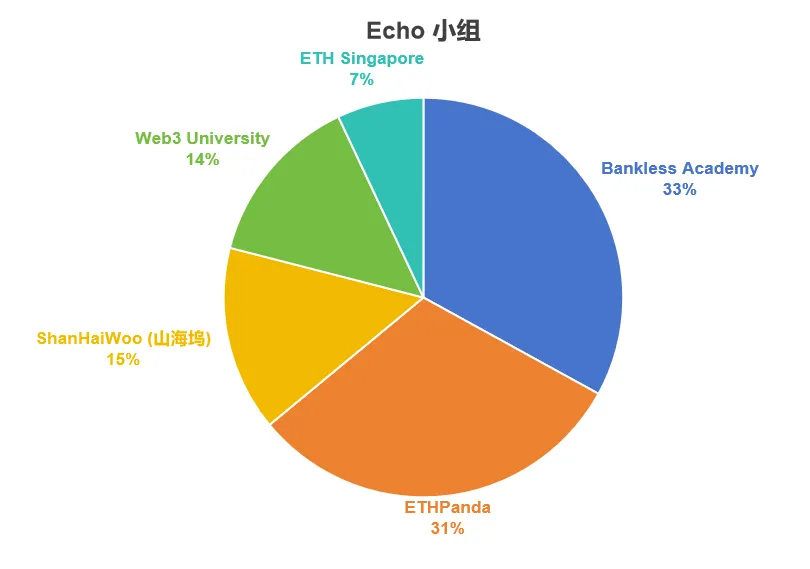
Echo 小组分配结果
| 项目名称 | 分配金额 (USD) | 分配比例 |
|---|---|---|
| Bankless Academy | 33,000 | 33% |
| ETHPanda | 31,000 | 31% |
| ShanHaiWoo | 15,000 | 15% |
| Web3 University | 14,000 | 14% |
| ETH Singapore | 7,000 | 7% |
| 总计 | 100,000 | 100% |
2.6 Stariv 小组 — 社区活动与体验闭环
独特点:该小组把“公共物品”从传统教育或治理工具转向了社区活动与体验型项目,聚焦 Web3 社区活动闭环,如:
-
新人欢迎会
-
Builder 工作坊
-
职业发展圆桌
-
治理模拟游戏
-
项目展示夜
他们强调活动设计的不同价值,包括社交价值、技能收获、网络机会等,并提出了一整套分配策略和讨论机制。
这类策略体现了一种更具体的“公共物品”视角:通过体验与活动提高社区认知、互动和协作能力。
Stativ 小组分配结果
| 活动名称 | 分配金额 (USD) | 分配比例 |
|---|---|---|
| 治理模拟游戏 | 29,290 | 29.29% |
| Builder工作坊 | 26,430 | 26.43% |
| 项目展示夜 | 21,430 | 21.43% |
| 新人欢迎会 | 11,860 | 11.86% |
| 职业发展圆桌 | 10,570 | 10.57% |
| 总计 | 100,000 | 100% |

三、治理过程中的趣事与共识
在这些讨论中,几个有趣的治理洞察频繁出现:
 1. “好人/坏人”博弈增强参与感
1. “好人/坏人”博弈增强参与感
很多小组介绍了游戏背景里的“行动者(坏人)”设定,这一角色未知的机制増加了讨论中的策略性和不确定性,让参与者不仅讨论分配,还要在言论中考虑隐蔽策略。
2. 投票 + 分配权重机制本身就是实验
如在 Jintol 小组,有成员提出以“发帖权重”评估贡献并据此分配资金,这是治理参与性的一个直接实验。
3. 讨论中出现“怀疑论”
有些成员因为某些项目被大多数人提名,开始探讨是否存在组织性投票影响(类似社会博弈、策略投票),这正是 DAO 环境中真实治理中可能出现的群体行为偏差。
四、治理问题与潜在解决方法建议
4.1 治理冷漠性
许多讨论反映出参与人数实际少于小组规模,这种“冷漠”会削弱治理质量。
![]() 解决建议
解决建议
-
引入更精细化的贡献计量(如发帖/评估贡献 + 实际投票权);
-
鼓励早期参与激励机制,例如对有效评论、深入分析提供奖励;
-
通过自动提醒和任务式引导提高整体参与度。
4.2 评估标准不统一
各组用的权重与评估指标差异很大,导致分配策略方向存在偏差。
![]() 解决建议
解决建议
-
制定统一的项目评估框架(例如:教学质量、可及性、长期价值、生态协同性);
-
提供评估模板或表格帮助成员量化判断;
-
定期复盘评估体系结果并迭代。
4.3 策略性投票与集体偏见风险
出现了成员担心项目被多数押注导致集体战略方向偏向某些大项目。
![]() 解决建议
解决建议
-
实施多阶段投票机制:初选 + 优化方案投票;
-
引入负反馈机制,如对过度倾斜项目设定资金上限;
-
建立透明的理由公示区,让意见领袖更公开解释自己立场。
五、治理洞察:公共物品资金分配中暴露的 5 个核心问题
5.1 公共物品定义不统一
现象
在各小组讨论中,“公共物品”被同时指向教育项目、治理工具、社区活动等不同类型。不同成员对公共物品的边界理解差异很大,导致各组的分配逻辑天然不一致。
影响
当公共物品缺少统一定义时,资金分配会更像“偏好投票”,而不是“共识治理”。最终结果难以形成长期稳定的方向,也难以对外解释。
潜在解法
-
明确资金池支持范围(例如教育 / 工具 / 活动分赛道)
-
建立最小共识定义:什么算公共物品,什么不算
-
对不同赛道采用不同评估指标,避免混合比较
5.2 资金分配目标不一致(集中 vs 分散)
现象
讨论中反复出现两种典型倾向:
-
集中投入头部项目,追求确定性与影响力最大化
-
分散支持多个项目,追求生态多样性与风险分散
影响
当资金目标不明确时,治理讨论容易陷入“策略争论”,而不是对项目本身的评估。更重要的是,分配结果会高度依赖当期参与者的价值取向,难以沉淀长期规则。
潜在解法
-
在每轮分配前先明确资金池目标(增长 / 多样性 / 实验 / 稳健)
-
设定集中度上限或探索预算(例如 70% 稳健 + 30% 探索)
-
将“分配策略”作为投票的一部分,而不是隐含假设
5.3 缺少统一评估框架
现象
虽然大家都在认真讨论,但评价维度并不一致:有人看影响力,有人看可持续性,有人看开源程度,有人看协作潜力。很多争论本质上不是项目优劣,而是指标体系不同。
影响
缺少统一框架会导致:
-
讨论成本升高,容易跑题
-
最终结果更像“意见博弈”
-
治理经验难复用,下一轮又从零开始
潜在解法
-
建立统一评估表(例如公共性/影响力/可持续性/生态协同/执行能力)
-
要求投票附理由,并对应到指标维度
-
将评估模板标准化,降低参与成本
5.4 信息不对称影响决策公平性
现象
不同成员对项目的熟悉程度差异极大:有些人非常了解项目背景与质量,有些人只能根据他人的描述进行判断,甚至直接跟随主流观点。
影响
这会产生一种隐形权力结构:
熟悉信息的人天然更有影响力,而不熟悉的人更难做出独立判断。最终治理结果可能更接近“信息优势者的偏好”,而非群体共识。
潜在解法
-
提供统一的项目资料包(背景、数据、开源情况、影响力证明)
-
引入“信息贡献者/研究员”角色,把信息整理纳入贡献
-
在讨论中区分“事实信息”和“个人观点”,减少误导
5.5 缺少事后验证与复盘闭环
现象
大多数讨论停留在“如何分配”本身,但对资金发出后的效果如何验证、如何复盘、如何迭代规则,缺少明确机制。
影响
如果没有事后闭环,资金分配容易变成一次性行为:
无法判断项目是否真正产生公共价值,也无法沉淀治理经验,导致每轮分配都重复同样的争论。
潜在解法
-
设立事后复盘机制(例如 1-3 个月后回访与成果汇报)
-
引入轻量级指标追踪(如使用量、贡献者增长、内容产出等)
-
将复盘结果反馈到下一轮评估权重中,形成治理迭代
6. 如何进一步优化「良心杀」机制(含隐私与反博弈设计)
6.1 引入“隐私投票”或“半隐私讨论”机制(降低策略投票)
目前论坛讨论是完全公开的,容易出现:
-
观点被带节奏
-
成员提前表态后难以修正
-
项目方/熟人影响讨论
建议机制:
-
第一阶段匿名/半匿名打分(每人独立提交评分)
-
第二阶段公开讨论(基于聚合结果讨论差异)
-
第三阶段最终投票(可公开或继续匿名)
这会显著降低“从众效应”和策略表达。
6.2 引入统一的“项目资料包”,减少信息不对称
每个候选项目提供一页标准资料:
-
目标与受众
-
过去 6-12 个月成果
-
公开数据(用户、贡献者、内容量)
-
开源程度
-
资金使用方式与 runway
这样讨论会从“印象”转向“事实”。
6.3 机制上拆分:先投策略,再投分配
建议把流程拆成两层:
1)投票决定:本轮资金池的分配哲学
- 集中 / 分散 / 70-30 / 50-50
2)再进入项目分配
这样能减少价值观冲突,提高共识效率。
6.4 引入“复盘权重”:把历史表现纳入下一轮
如果未来良心杀要长期运行,建议加入轻量闭环:
-
资金发放后 1-3 个月项目提交成果
-
社区给出复盘评分
-
评分影响下一轮“可信度/基础权重”
这样公共物品分配会逐渐形成“治理记忆”。
7. 结语:良心杀的价值不在结果,而在治理训练
本轮良心杀并不是为了找到“唯一正确”的分配答案,而是让社区在低成本环境中体验并暴露真实治理难题:价值观差异、信息不对称、策略行为与缺少闭环。
从这个意义上看,良心杀已经完成了它最重要的任务:
它把 DAO 治理从抽象理念变成了可讨论、可复盘、可迭代的协作实践。